OpenAI開(kāi)發(fā)系列(二) 大語(yǔ)言模型發(fā)展史與Transformer架構(gòu)詳解
隨著人工智能技術(shù)的飛速發(fā)展,大語(yǔ)言模型已成為推動(dòng)自然語(yǔ)言處理領(lǐng)域的核心驅(qū)動(dòng)力。本文將從計(jì)算機(jī)軟硬件開(kāi)發(fā)及銷(xiāo)售的角度,系統(tǒng)梳理大語(yǔ)言模型的發(fā)展歷程,并深入解析作為其基石的Transformer架構(gòu)。
一、大語(yǔ)言模型發(fā)展史:從理論到商業(yè)化的演進(jìn)
大語(yǔ)言模型的發(fā)展,離不開(kāi)計(jì)算機(jī)軟硬件技術(shù)的持續(xù)迭代與商業(yè)化應(yīng)用。其演進(jìn)路徑可概括為三個(gè)階段:
- 早期探索與統(tǒng)計(jì)模型階段(20世紀(jì)90年代-2010年代):此階段的模型以統(tǒng)計(jì)方法為主,如N-gram模型和隱馬爾可夫模型。這些模型受限于計(jì)算能力和數(shù)據(jù)規(guī)模,通常依賴(lài)于特定領(lǐng)域的小規(guī)模數(shù)據(jù),且商業(yè)化應(yīng)用集中在語(yǔ)音識(shí)別、基礎(chǔ)文本分類(lèi)等有限場(chǎng)景。硬件以CPU為主流,軟件實(shí)現(xiàn)相對(duì)簡(jiǎn)單。
- 深度學(xué)習(xí)與神經(jīng)網(wǎng)絡(luò)興起階段(2010年代-2017年):隨著GPU在并行計(jì)算上的優(yōu)勢(shì)被發(fā)掘,以及深度學(xué)習(xí)框架(如TensorFlow、PyTorch)的成熟,神經(jīng)網(wǎng)絡(luò)模型開(kāi)始主導(dǎo)。基于循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)和長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(LSTM)的序列模型得到廣泛應(yīng)用,推動(dòng)了機(jī)器翻譯、情感分析等商業(yè)化產(chǎn)品的落地。RNN系列模型存在訓(xùn)練效率低、長(zhǎng)程依賴(lài)處理能力弱等瓶頸。
- Transformer時(shí)代與大模型商業(yè)化爆發(fā)(2017年至今):2017年,Google在論文《Attention Is All You Need》中提出Transformer架構(gòu),徹底改變了自然語(yǔ)言處理的范式。OpenAI、Google、Meta等機(jī)構(gòu)基于Transformer相繼推出GPT系列、BERT、T5等大語(yǔ)言模型。這些模型參數(shù)規(guī)模從數(shù)億擴(kuò)展到數(shù)千億,依賴(lài)高性能GPU集群(如NVIDIA A100/H100)和分布式訓(xùn)練框架進(jìn)行開(kāi)發(fā)。在銷(xiāo)售與應(yīng)用層面,大語(yǔ)言模型通過(guò)API服務(wù)(如OpenAI的GPT API)、云平臺(tái)集成和行業(yè)解決方案等形式,廣泛賦能搜索引擎、智能客服、內(nèi)容生成、代碼輔助等商業(yè)場(chǎng)景,形成了從硬件(專(zhuān)用AI芯片、服務(wù)器)到軟件(預(yù)訓(xùn)練模型、微調(diào)工具)再到服務(wù)(SaaS、定制化開(kāi)發(fā))的完整產(chǎn)業(yè)鏈。
二、Transformer架構(gòu)詳解:驅(qū)動(dòng)大語(yǔ)言模型的核心引擎
Transformer是一種完全基于自注意力機(jī)制的神經(jīng)網(wǎng)絡(luò)架構(gòu),其設(shè)計(jì)兼顧了高效并行計(jì)算與強(qiáng)大的序列建模能力,成為當(dāng)前大語(yǔ)言模型的標(biāo)配。下面從計(jì)算機(jī)實(shí)現(xiàn)的角度解析其核心組件:
- 自注意力機(jī)制(Self-Attention):這是Transformer的核心創(chuàng)新。通過(guò)計(jì)算輸入序列中每個(gè)詞與其他詞的相關(guān)性權(quán)重,模型能夠動(dòng)態(tài)捕捉長(zhǎng)距離依賴(lài)關(guān)系。從硬件角度看,自注意力的大規(guī)模矩陣運(yùn)算非常契合GPU的并行計(jì)算特性,顯著提升了訓(xùn)練和推理效率。軟件實(shí)現(xiàn)上,通常采用優(yōu)化后的矩陣庫(kù)(如CUDA加速)來(lái)保證計(jì)算速度。
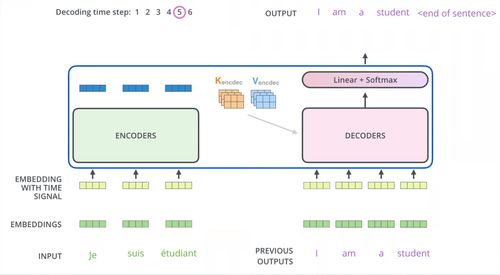
- 編碼器-解碼器結(jié)構(gòu):原始Transformer包含編碼器和解碼器堆棧。編碼器用于理解輸入序列,解碼器用于生成輸出序列。在如BERT等模型中僅使用編碼器,而GPT系列僅使用解碼器。這種模塊化設(shè)計(jì)便于軟件層面的靈活調(diào)整與復(fù)用,支持不同任務(wù)(如理解vs.生成)的模型開(kāi)發(fā)。
- 位置編碼(Positional Encoding):由于Transformer本身不具備序列順序信息,需要通過(guò)位置編碼為輸入添加位置信息。常見(jiàn)方式包括正弦余弦編碼或可學(xué)習(xí)的位置嵌入。這一機(jī)制在軟件實(shí)現(xiàn)上簡(jiǎn)單高效,無(wú)需如RNN那樣的遞歸計(jì)算。
- 前饋神經(jīng)網(wǎng)絡(luò)與殘差連接:每個(gè)注意力層后接一個(gè)前饋網(wǎng)絡(luò),并采用殘差連接和層歸一化來(lái)穩(wěn)定深度網(wǎng)絡(luò)的訓(xùn)練。這有助于緩解梯度消失問(wèn)題,使得訓(xùn)練超深層模型(如GPT-3的1750億參數(shù))成為可能,這對(duì)硬件(大內(nèi)存、高帶寬)和軟件(梯度優(yōu)化、分布式訓(xùn)練)提出了極高要求。
- 規(guī)模化與硬件協(xié)同:Transformer架構(gòu)的擴(kuò)展性極強(qiáng),模型性能隨參數(shù)規(guī)模和數(shù)據(jù)量增加而顯著提升。這驅(qū)動(dòng)了專(zhuān)用AI硬件(如TPU、AI加速卡)的研發(fā)與銷(xiāo)售,以及配套軟件棧(如DeepSpeed、Megatron-LM)的優(yōu)化,以降低大規(guī)模訓(xùn)練的復(fù)雜度和成本。
大語(yǔ)言模型的發(fā)展史,本質(zhì)上是算法創(chuàng)新、計(jì)算硬件升級(jí)與商業(yè)化探索交織的歷程。Transformer架構(gòu)以其卓越的并行能力和擴(kuò)展性,成為這一進(jìn)程的關(guān)鍵轉(zhuǎn)折點(diǎn)。對(duì)于從事計(jì)算機(jī)軟硬件開(kāi)發(fā)及銷(xiāo)售的企業(yè)與開(kāi)發(fā)者而言,深入理解Transformer的原理及其在硬件加速、軟件框架和云端服務(wù)中的應(yīng)用,是把握AI時(shí)代商業(yè)機(jī)遇的重要基礎(chǔ)。隨著模型壓縮、邊緣計(jì)算等技術(shù)的發(fā)展,大語(yǔ)言模型有望進(jìn)一步向低成本、高能效的方向演進(jìn),開(kāi)拓更廣闊的軟硬件市場(chǎng)空間。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.tyfy.com.cn/product/62.html
更新時(shí)間:2026-06-13 22:16:23